1)发现问题
最近在生产环境中,发现了有趣的问题:有一个业务用到了Redis的RANDOMKEY命令获取随机的key,因为开发测试时数据量都从大的范围考虑,也没仔细思考虑RANDOMKEY够不够随机,并且生产环境在存在大量key的情况下,从运营那边的反馈来看,是随机得比较均匀的。后来在一个新的渠道中,KEY变少了,运营跟我说,接口返回的结果大数据量的统计发现不均匀。本来我的态度是:随机的东西,也不是100%均匀的嘛。但是连续几天都发现比较大的偏差,并且发生在KEY量级在个位数级别的时候。于是我开始思考问题的根源。
2)探索源码
先检出源码到本地磁盘吧!
git clone https://github.com/antirez/redis.git redis-src
cd redis-src
好了,源码是C语言的,为了解决问题我才来阅读,也是头一回阅读了。虽然早期学过C语言,但那是六年前的事了,四舍五入就是看不明白也不懂结构。那怎么办呢?好在搜索大法好,直接以命令名为关键字搜索RANDOMKEY吧:
find .|xargs grep -ri "RANDOMKEY"
下面这两行成功的引起了我的注意
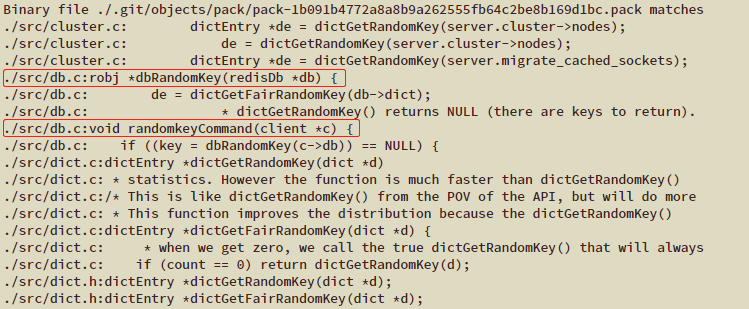
于是我打开./src/db.c文件找到这两行所在位置
// ...
/* Return a random key, in form of a Redis object.
* If there are no keys, NULL is returned.
*
* The function makes sure to return keys not already expired. */
robj *dbRandomKey(redisDb *db) {
dictEntry *de;
int maxtries = 100;
int allvolatile = dictSize(db->dict) == dictSize(db->expires);
while(1) {
sds key;
robj *keyobj;
de = dictGetFairRandomKey(db->dict);
if (de == NULL) return NULL;
key = dictGetKey(de);
keyobj = createStringObject(key,sdslen(key));
if (dictFind(db->expires,key)) {
if (allvolatile && server.masterhost && --maxtries == 0) {
/* If the DB is composed only of keys with an expire set,
* it could happen that all the keys are already logically
* expired in the slave, so the function cannot stop because
* expireIfNeeded() is false, nor it can stop because
* dictGetRandomKey() returns NULL (there are keys to return).
* To prevent the infinite loop we do some tries, but if there
* are the conditions for an infinite loop, eventually we
* return a key name that may be already expired. */
return keyobj;
}
if (expireIfNeeded(db,keyobj)) {
decrRefCount(keyobj);
continue; /* search for another key. This expired. */
}
}
return keyobj;
}
}
// ...
void randomkeyCommand(client *c) {
robj *key;
if ((key = dbRandomKey(c->db)) == NULL) {
addReplyNull(c);
return;
}
addReplyBulk(c,key);
decrRefCount(key);
}
// ...
可以看到,randomkeyCommand函数内部调用了dbRandomKey函数,dbRandomKey函数内又是通过dictGetFairRandomKey得到的key
在当前文件中没有找到dictGetFairRandomKey函数的实现,从刚刚的搜索结果中发现其实现写在了./src/dict.c文件内,于是打开查看:
// ...
/* This is like dictGetRandomKey() from the POV of the API, but will do more
* work to ensure a better distribution of the returned element.
*
* This function improves the distribution because the dictGetRandomKey()
* problem is that it selects a random bucket, then it selects a random
* element from the chain in the bucket. However elements being in different
* chain lengths will have different probabilities of being reported. With
* this function instead what we do is to consider a "linear" range of the table
* that may be constituted of N buckets with chains of different lengths
* appearing one after the other. Then we report a random element in the range.
* In this way we smooth away the problem of different chain lenghts. */
#define GETFAIR_NUM_ENTRIES 15
dictEntry *dictGetFairRandomKey(dict *d) {
dictEntry *entries[GETFAIR_NUM_ENTRIES];
unsigned int count = dictGetSomeKeys(d,entries,GETFAIR_NUM_ENTRIES);
/* Note that dictGetSomeKeys() may return zero elements in an unlucky
* run() even if there are actually elements inside the hash table. So
* when we get zero, we call the true dictGetRandomKey() that will always
* yeld the element if the hash table has at least one. */
if (count == 0) return dictGetRandomKey(d);
unsigned int idx = rand() % count;
return entries[idx];
}
// ...
看了这个函数的描述,作者其实是知道随机不公平这种情况的,并且这个函数就是为了解决这个问题。但是这个函数并不保证返回的结果具有良好的分布,说白了就是这里的算法依然是不公平的。这个时候由于不懂redis的数据结构,所以这段注释也是不太理解的。
3)Redis数据结构dict
于是我们应该先了解一下dict的结构了,打开./src/dict.h查看
// ...
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
// ...
为了理解这一数据结构,我参考了以下博文:
Redis 数据结构 dict
Redis内部数据结构详解(1)——dict
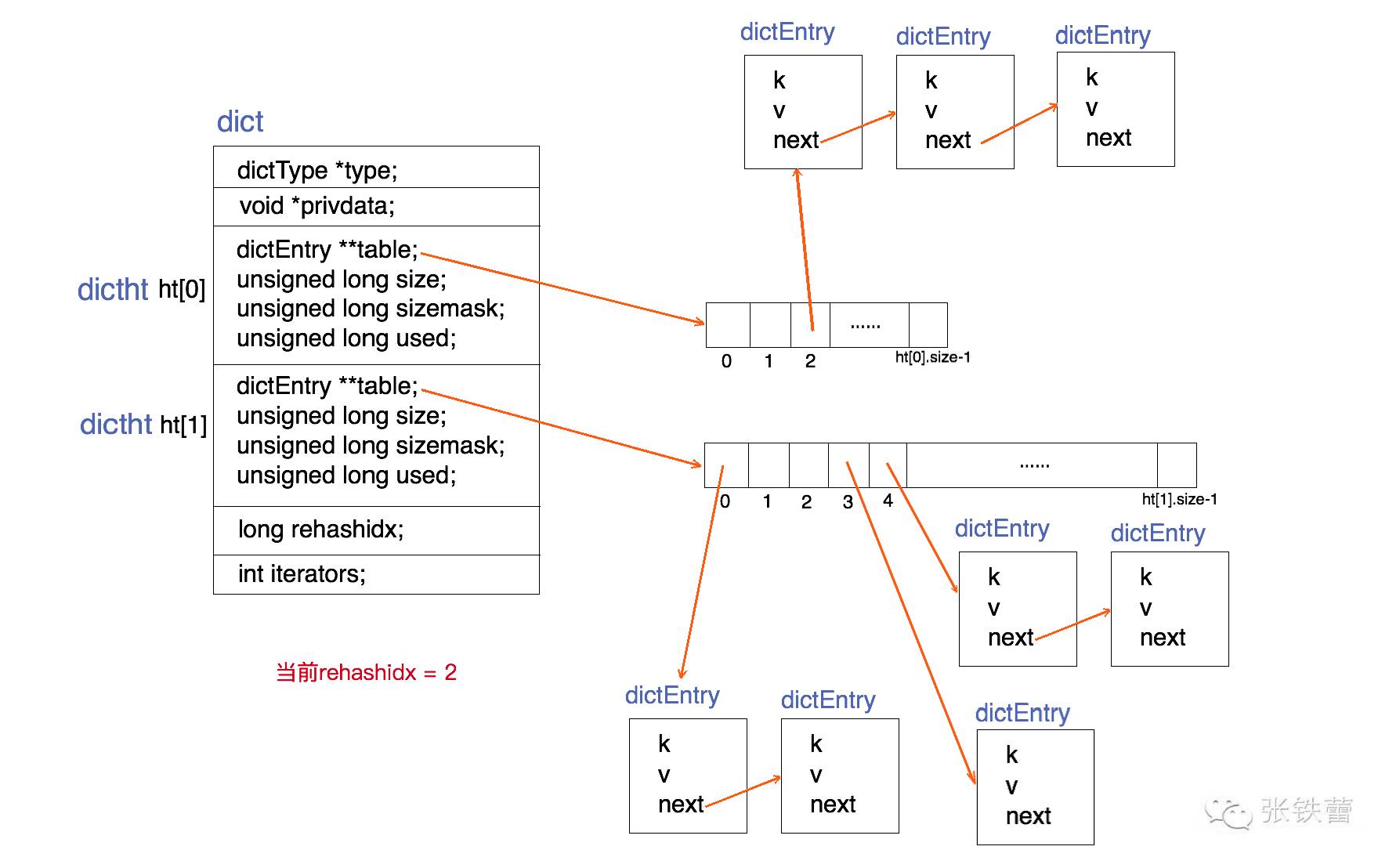
从上图中可以看出,这是一个数组加链表的结构,我这就不进行重复解释了,上面两篇博文写得也比较清晰。
理解了dict的结构之后,我们再继续阅读dictGetSomeKeys和dictGetRandomKey函数的实现
4)随机函数的实现
dictGetSomeKeys
// ...
/* This function samples the dictionary to return a few keys from random
* locations.
*
* It does not guarantee to return all the keys specified in 'count', nor
* it does guarantee to return non-duplicated elements, however it will make
* some effort to do both things.
*
* Returned pointers to hash table entries are stored into 'des' that
* points to an array of dictEntry pointers. The array must have room for
* at least 'count' elements, that is the argument we pass to the function
* to tell how many random elements we need.
*
* The function returns the number of items stored into 'des', that may
* be less than 'count' if the hash table has less than 'count' elements
* inside, or if not enough elements were found in a reasonable amount of
* steps.
*
* Note that this function is not suitable when you need a good distribution
* of the returned items, but only when you need to "sample" a given number
* of continuous elements to run some kind of algorithm or to produce
* statistics. However the function is much faster than dictGetRandomKey()
* at producing N elements. */
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count) {
unsigned long j; /* internal hash table id, 0 or 1. */
unsigned long tables; /* 1 or 2 tables? */
unsigned long stored = 0, maxsizemask;
unsigned long maxsteps;
if (dictSize(d) < count) count = dictSize(d);
maxsteps = count*10;
/* Try to do a rehashing work proportional to 'count'. */
for (j = 0; j < count; j++) {
if (dictIsRehashing(d))
_dictRehashStep(d);
else
break;
}
tables = dictIsRehashing(d) ? 2 : 1;
maxsizemask = d->ht[0].sizemask;
if (tables > 1 && maxsizemask < d->ht[1].sizemask)
maxsizemask = d->ht[1].sizemask;
/* Pick a random point inside the larger table. */
unsigned long i = random() & maxsizemask;
unsigned long emptylen = 0; /* Continuous empty entries so far. */
while(stored < count && maxsteps--) {
for (j = 0; j < tables; j++) {
/* Invariant of the dict.c rehashing: up to the indexes already
* visited in ht[0] during the rehashing, there are no populated
* buckets, so we can skip ht[0] for indexes between 0 and idx-1. */
if (tables == 2 && j == 0 && i < (unsigned long) d->rehashidx) {
/* Moreover, if we are currently out of range in the second
* table, there will be no elements in both tables up to
* the current rehashing index, so we jump if possible.
* (this happens when going from big to small table). */
if (i >= d->ht[1].size)
i = d->rehashidx;
else
continue;
}
if (i >= d->ht[j].size) continue; /* Out of range for this table. */
dictEntry *he = d->ht[j].table[i];
/* Count contiguous empty buckets, and jump to other
* locations if they reach 'count' (with a minimum of 5). */
if (he == NULL) {
emptylen++;
if (emptylen >= 5 && emptylen > count) {
i = random() & maxsizemask;
emptylen = 0;
}
} else {
emptylen = 0;
while (he) {
/* Collect all the elements of the buckets found non
* empty while iterating. */
*des = he;
des++;
he = he->next;
stored++;
if (stored == count) return stored;
}
}
}
i = (i+1) & maxsizemask;
}
return stored;
}
// ...
由于redis的数据结构是数组加链表的形式实现,从上面的代码中可以看出,
函数中先生成一个0到maxsizemask(两个数组中最长的一个的长度-1)长度的一个数,
以随机命中数组中的一个元素,命中这个元素后,
会将这个元素以及尾随的节点一起存到des指针指向的数组,
直到已经获得了count个元素或者已走完count*10步;
最后在dictGetFairRandomKey函数中从数组中随机取了一个;
由此可见,图中的各个字母概率根本不一致
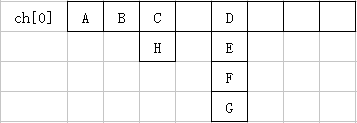
按照这个算法,暂不考虑重哈希过程,
A、B的概率为1/5,
C、H的概率为1/5 * 1/2 = 1/10,
剩余元素的概率为2/5 * 1/4 = 3/20,
因为当随机数落到C与D之间的空格中,会由于i = (i+1) & maxsizemask;这句话的缘故进而在下次循环中命中D列,
所以第一个分母是5。
那如果dictGetSomeKeys没有命中到元素,我们就看看dictGetRandomKey里面的算法有何不一样吧
dictGetRandomKey
// ...
/* Return a random entry from the hash table. Useful to
* implement randomized algorithms */
dictEntry *dictGetRandomKey(dict *d)
{
dictEntry *he, *orighe;
unsigned long h;
int listlen, listele;
if (dictSize(d) == 0) return NULL;
if (dictIsRehashing(d)) _dictRehashStep(d);
if (dictIsRehashing(d)) {
do {
/* We are sure there are no elements in indexes from 0
* to rehashidx-1 */
h = d->rehashidx + (random() % (d->ht[0].size +
d->ht[1].size -
d->rehashidx));
he = (h >= d->ht[0].size) ? d->ht[1].table[h - d->ht[0].size] :
d->ht[0].table[h];
} while(he == NULL);
} else {
do {
h = random() & d->ht[0].sizemask;
he = d->ht[0].table[h];
} while(he == NULL);
}
/* Now we found a non empty bucket, but it is a linked
* list and we need to get a random element from the list.
* The only sane way to do so is counting the elements and
* select a random index. */
listlen = 0;
orighe = he;
while(he) {
he = he->next;
listlen++;
}
listele = random() % listlen;
he = orighe;
while(listele--) he = he->next;
return he;
}
// ...
这个算法看上去比较容易理解,继续拿上面那张图来计算概率:
A、B的概率为1/4,
C、H的概率为1/4 * 1/2 = 1/10,
剩余元素的概率为2/4 * 1/4 = 3/16
跟上面的函数不一样的地方在于这个函数如果命中数组中的空元素会重新生成随机数。
但是各个元素的概率依然不一致。
怎么解决这个问题呢?
5) 解题思路
概率不均匀的原因在哪里?
如果我们吧A的概率看成是1/4 * 1,C的概率为1/4 * 1/2,
就会发现:破坏概率的是C和D的后续节点,也就是链表的出现破坏了概率。
链表表示很委屈。。。
那也没办法,找一下如何让链表消失,评估一下代价。
那就要查看数组扩容部分的代码了,
记得以前学习数据结构的时候,数组的扩张是发生在增加元素并且空间不够时,
那我们就找一下负责添加元素的函数吧。
在./src/dict.c文件中搜索add关键字,发现可疑目标函数
// ...
/* Add an element to the target hash table */
int dictAdd(dict *d, void *key, void *val)
{
dictEntry *entry = dictAddRaw(d,key,NULL);
if (!entry) return DICT_ERR;
dictSetVal(d, entry, val);
return DICT_OK;
}
// ...
没错就是它了。进去dictAddRaw函数看看吧
// ...
/* Low level add or find:
* This function adds the entry but instead of setting a value returns the
* dictEntry structure to the user, that will make sure to fill the value
* field as he wishes.
*
* This function is also directly exposed to the user API to be called
* mainly in order to store non-pointers inside the hash value, example:
*
* entry = dictAddRaw(dict,mykey,NULL);
* if (entry != NULL) dictSetSignedIntegerVal(entry,1000);
*
* Return values:
*
* If key already exists NULL is returned, and "*existing" is populated
* with the existing entry if existing is not NULL.
*
* If key was added, the hash entry is returned to be manipulated by the caller.
*/
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d);
/* Get the index of the new element, or -1 if
* the element already exists. */
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
return NULL;
/* Allocate the memory and store the new entry.
* Insert the element in top, with the assumption that in a database
* system it is more likely that recently added entries are accessed
* more frequently. */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
entry = zmalloc(sizeof(*entry));
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
/* Set the hash entry fields. */
dictSetKey(d, entry, key);
return entry;
}
// ...
发现这个函数有一个查找该key是否已经存在的函数_dictKeyIndex,进去看看吧。
// ...
/* Returns the index of a free slot that can be populated with
* a hash entry for the given 'key'.
* If the key already exists, -1 is returned
* and the optional output parameter may be filled.
*
* Note that if we are in the process of rehashing the hash table, the
* index is always returned in the context of the second (new) hash table. */
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
/* Expand the hash table if needed */
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
for (table = 0; table <= 1; table++) {
idx = hash & d->ht[table].sizemask;
/* Search if this slot does not already contain the given key */
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
if (!dictIsRehashing(d)) break;
}
return idx;
}
// ...
发现可疑函数_dictExpandIfNeeded,根据描述可以确定扩容的函数就是它了。
只是,我有点好奇,为什么扩容的操作会在一个查找函数中被触发?
而不是直接写到上一层函数dictAdd中呢?
// ...
/* Expand the hash table if needed */
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
// ...
从这个函数中不难发现,扩容的条件除了dict_can_resize参数之外还由dict_force_resize_ratio的值决定,当哈希表中元素的数量超过数组大小的5倍时强制扩容,
从redis.conf中并没有找到这两个配置参数,
不想跟踪dictEnableResize和dictDisableResize函数的调用,
直接改源码修改dict_force_resize_ratio的值为0重新编译吧!
// ...
/* Using dictEnableResize() / dictDisableResize() we make possible to
* enable/disable resizing of the hash table as needed. This is very important
* for Redis, as we use copy-on-write and don't want to move too much memory
* around when there is a child performing saving operations.
*
* Note that even when dict_can_resize is set to 0, not all resizes are
* prevented: a hash table is still allowed to grow if the ratio between
* the number of elements and the buckets > dict_force_resize_ratio. */
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;
// ...
6)修改Redis 5.0的Dockerfile
从https://hub.docker.com 中找到Redis的镜像的Dockerfile,并从GitHub中拿下来,在Dockerfile中下载解压源码后的代码后增加一段修改源代码的命令
# In order to make the random algorithm fairer, for command: RONDOMKEY
sed -i 's/static unsigned int dict_force_resize_ratio = 5;/static unsigned int dict_force_resize_ratio = 0;/g' /usr/src/redis/src/dict.c; \
修改后如下
# ...
wget -O redis.tar.gz "$REDIS_DOWNLOAD_URL"; \
echo "$REDIS_DOWNLOAD_SHA *redis.tar.gz" | sha256sum -c -; \
mkdir -p /usr/src/redis; \
tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1; \
rm redis.tar.gz; \
\
# disable Redis protected mode [1] as it is unnecessary in context of Docker
# (ports are not automatically exposed when running inside Docker, but rather explicitly by specifying -p / -P)
# [1]: https://github.com/antirez/redis/commit/edd4d555df57dc84265fdfb4ef59a4678832f6da
grep -q '^#define CONFIG_DEFAULT_PROTECTED_MODE 1$' /usr/src/redis/src/server.h; \
sed -ri 's!^(#define CONFIG_DEFAULT_PROTECTED_MODE) 1$!\1 0!' /usr/src/redis/src/server.h; \
grep -q '^#define CONFIG_DEFAULT_PROTECTED_MODE 0$' /usr/src/redis/src/server.h; \
# In order to make the random algorithm fairer, for command: RONDOMKEY
sed -i 's/static unsigned int dict_force_resize_ratio = 5;/static unsigned int dict_force_resize_ratio = 0;/g' /usr/src/redis/src/dict.c; \
# for future reference, we modify this directly in the source instead of just supplying a default configuration flag because apparently "if you specify any argument to redis-server, [it assumes] you are going to specify everything"
# see also https://github.com/docker-library/redis/issues/4#issuecomment-50780840
# (more exactly, this makes sure the default behavior of "save on SIGTERM" stays functional by default)
\
make -C /usr/src/redis -j "$(nproc)"; \
make -C /usr/src/redis install; \
# ...
好吧重新编译
docker build -t itmx/redis-dict-not-linked:5.0 .
7)测试
先运行一个官方实例(对照组)和修改后的实例(实验组)
docker run --rm -d --name redis-test-default -p 6379:6379 redis:5.0
docker run --rm -d --name redis-test-modify -p 6380:6379 itmx/redis-dict-not-linked:5.0
再写一个用于插入测试数据的脚本loop.sh
#!/bin/bash
for((i=1;i<=10000;i++));
do
UUID=$(cat /proc/sys/kernel/random/uuid)
redis-cli set $UUID $UUID
done
在实验组多次执行上面的脚本,没有发现异常,表明大数据量的插入没有什么问题
执行flushall命令清空之后
接下来在两个实例中都存入以下数据
set 1fc78e9ac41443588a89d167d29118e4 1fc78e9ac41443588a89d167d29118e4
set 213756034d694cd0b66881c1a1006bd0 213756034d694cd0b66881c1a1006bd0
set 256238defe1843f49bb6788a367b23d0 256238defe1843f49bb6788a367b23d0
set 3fb3c93124a346d5ab004c46bb3bba15 3fb3c93124a346d5ab004c46bb3bba15
set 6504afcf58aa4dcbaea17035a244d99a 6504afcf58aa4dcbaea17035a244d99a
set 8db6b6a4f4fb44e0af575cea09dc926d 8db6b6a4f4fb44e0af575cea09dc926d
set bd5b21d59f7c4bcaa4a3ae07c4e1ea27 bd5b21d59f7c4bcaa4a3ae07c4e1ea27
set ce032bc0e5614b069bfac6774ac72673 ce032bc0e5614b069bfac6774ac72673
接下来用一段go代码进行测试
package main
import (
"fmt"
"github.com/gomodule/redigo/redis"
"math/rand"
"time"
)
var (
conn redis.Conn
e error
keys = [...]string{
"1fc78e9ac41443588a89d167d29118e4",
"213756034d694cd0b66881c1a1006bd0",
"256238defe1843f49bb6788a367b23d0",
"3fb3c93124a346d5ab004c46bb3bba15",
"6504afcf58aa4dcbaea17035a244d99a",
"8db6b6a4f4fb44e0af575cea09dc926d",
"bd5b21d59f7c4bcaa4a3ae07c4e1ea27",
"ce032bc0e5614b069bfac6774ac72673",
}
)
func init() {
//以时间作为初始化种子
rand.Seed(time.Now().UnixNano())
//实验组
conn, e = redis.Dial("tcp", "192.168.1.58:6380")
//对照组
//conn, e = redis.Dial("tcp", "192.168.1.58:6379")
if e != nil {
panic(e)
}
}
func RedisRandomKey() string {
if key, e := redis.String(conn.Do("RANDOMKEY")); e != nil {
if e == redis.ErrNil {
return "null"
}
panic(e)
} else {
return key
}
}
func RandomKey() string {
return keys[rand.Int()&(len(keys)-1)]
}
func loop(randFunc func() string) {
var result = make(map[string]int)
for i := 0; i < 1000; i++ {
key := randFunc()
result[key]++
}
fmt.Println()
for _, key := range keys {
fmt.Printf("%d\t", result[key])
}
}
func main() {
defer conn.Close()
for {
//使用Go语言的随机数进行测试
//loop(RandomKey)
//使用redis的RandomKey命令进行测试
loop(RedisRandomKey)
time.Sleep(2 * time.Second)
}
}
各取30组样本,实验结果:
对照组如下图
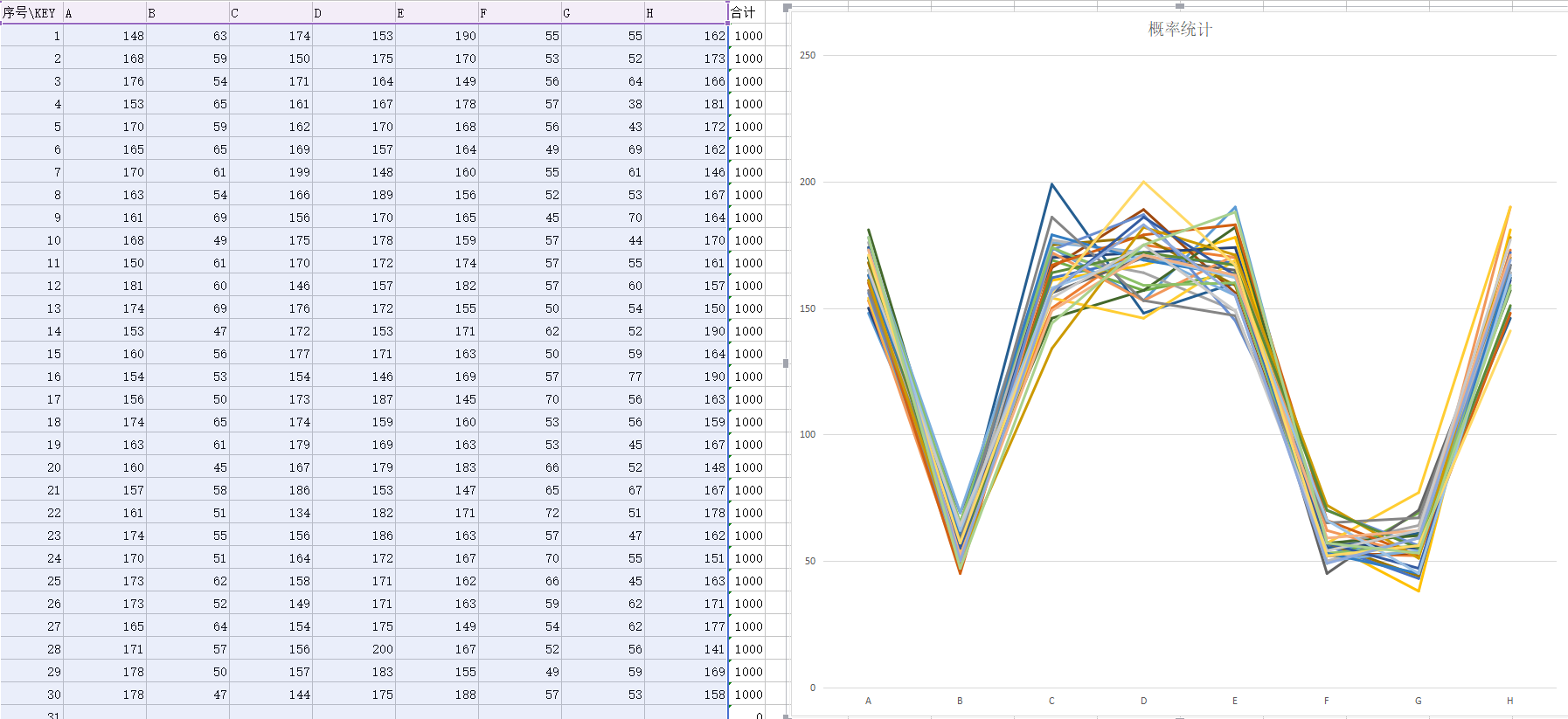
实验组如下图
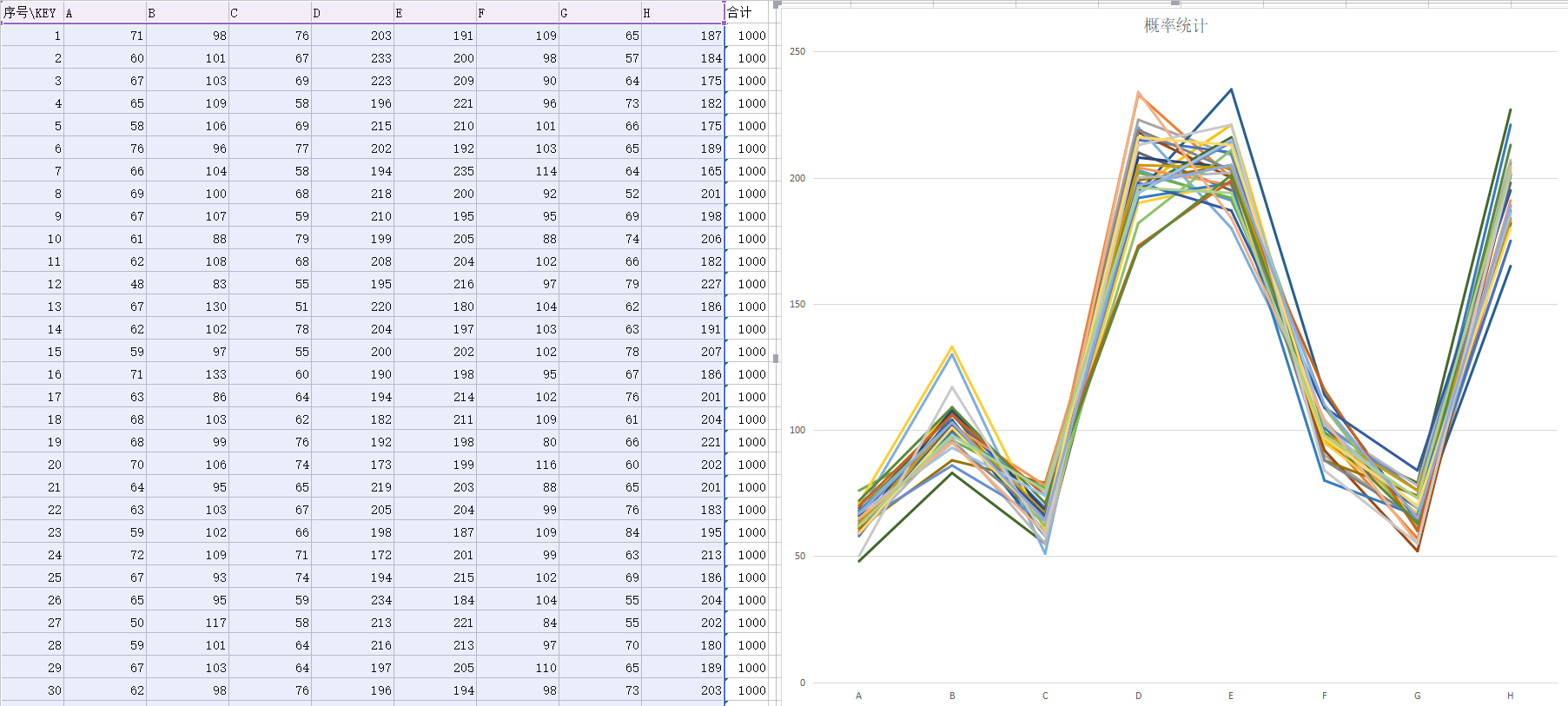
在附上一个实用go语言实现的随机结果
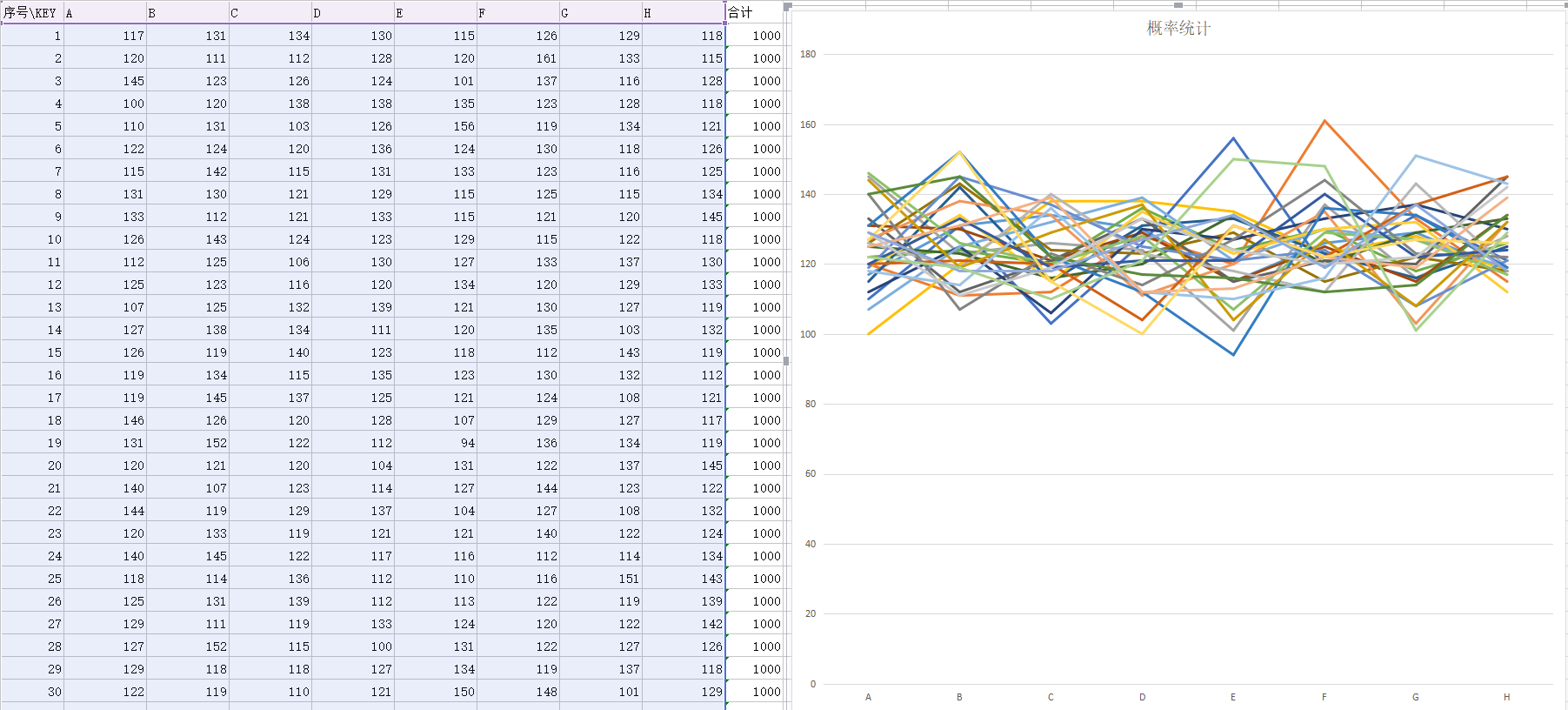
实验表明,我们的改动没有任何软用
其实仔细想想就知道了。
想把链表去掉单靠数组支撑是不可取的,
会导致每一次hash碰撞都需要扩容。
8)总结
虽然是C语言写的,但是往往在业务当中我们要解决的并不是语言的问题,而实逻辑的问题,所以,不要害怕它吧。虽然这一次尝试失败了。但还是学到了不少东西,比如按位与&和求模%运算,当第二个数满足2^n-1时,这两个运算符的结果一致,前者效率就要高一点了。
并且,越是优秀的项目,代码也会越规范,
阅读起来也比较舒服,所以,多阅读优秀开源项目的源码吧。
开源项目有什么不懂,看源码最直接了!!!